發布日期:2022-10-09 點擊率:35
前言:人工智能機器學習有關算法內容,人工智能之機器學習主要有三大類:1)分類;2)回歸;3)聚類。今天我們重點探討一下深度強化學習。
之前介紹過深度學習DL和強化學習RL,那么人們不禁會問會不會有深度強化學習DRL呢? 答案是Exactly!
我們先回顧一下深度學習DL和強化學習RL。
深度學習DL是機器學習中一種基于對數據進行表征學習的方法。深度學習DL有監督和非監督之分,都已經得到廣泛的研究和應用。
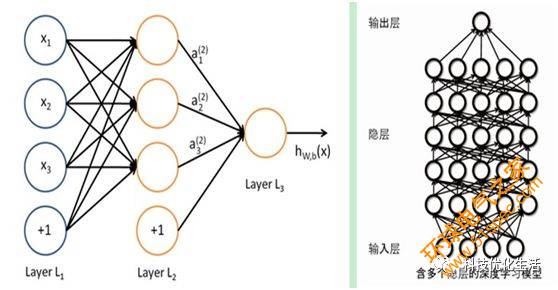
強化學習RL是通過對未知環境一邊探索一邊建立環境模型以及學習得到一個最優策略。強化學習是機器學習中一種快速、高效且不可替代的學習算法。
然后今天我們重點跟跟大家一起探討一下深度強化學習DRL。
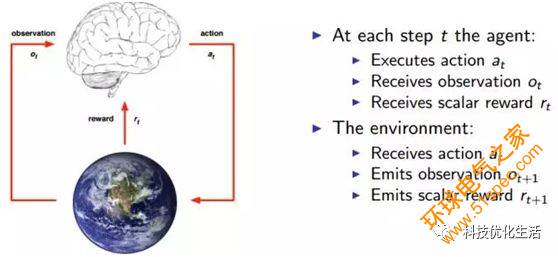
深度強化學習DRL自提出以來, 已在理論和應用方面均取得了顯著的成果。尤其是谷歌DeepMind團隊基于深度強化學習DRL研發的AlphaGo,將深度強化學習DRL成推上新的熱點和高度,成為人工智能歷史上一個新的里程碑。因此,深度強化學習DRL非常值得研究。
深度強化學習概念:
深度強化學習DRL將深度學習DL的感知能力和強化學習RL的決策能力相結合, 可以直接根據輸入的信息進行控制,是一種更接近人類思維方式的人工智能方法。
在與世界的正常互動過程中,強化學習會通過試錯法利用獎勵來學習。它跟自然學習過程非常相似,而與深度學習不同。在強化學習中,可以用較少的訓練信息,這樣做的優勢是信息更充足,而且不受監督者技能限制。
深度強化學習DRL是深度學習和強化學習的結合。這兩種學習方式在很大程度上是正交問題,二者結合得很好。強化學習定義了優化的目標,深度學習給出了運行機制——表征問題的方式以及解決問題的方式。將強化學習和深度學習結合在一起,尋求一個能夠解決任何人類級別任務的代理,得到了能夠解決很多復雜問題的一種能力——通用智能。深度強化學習DRL將有助于革新AI領域,它是朝向構建對視覺世界擁有更高級理解的自主系統邁出的一步。從某種意義上講,深度強化學習DRL是人工智能的未來。
深度強化學習本質:
深度強化學習DRL的Autonomous Agent使用強化學習的試錯算法和累計獎勵函數來加速神經網絡設計。這些設計為很多依靠監督/無監督學習的人工智能應用提供支持。它涉及對強化學習驅動Autonomous Agent的使用,以快速探索與無數體系結構、節點類型、連接、超參數設置相關的性能權衡,以及對深度學習、機器學習和其他人工智能模型設計人員可用的其它選擇。
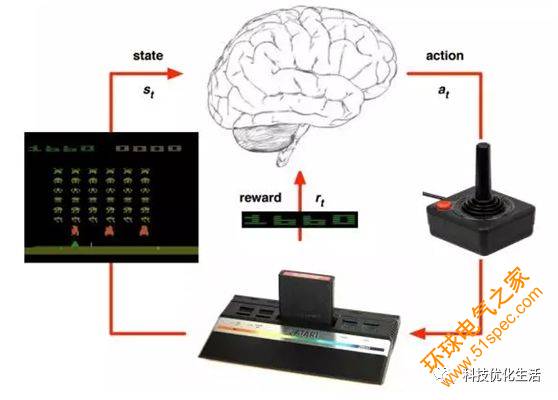
深度強化學習原理:
深度Q網絡通過使用深度學習DL和強化學習RL兩種技術,來解決在強化學習RL中使用函數逼近的基本不穩定性問題:經驗重放和目標網絡。經驗重放使得強化學習RL智能體能夠從先前觀察到的數據離線進行抽樣和訓練。這不僅大大減少了環境所需的交互量,而且可以對一批經驗進行抽樣,減少學習更新的差異。此外,通過從大存儲器均勻采樣,可能對強化學習RL算法產生不利影響的時間相關性被打破了。最后,從實際的角度看,可以通過現代硬件并行地高效地處理批量的數據,從而提高吞吐量。
Q學習的核心思想就是通過Bellman方程來迭代求解Q函數。

損失函數:
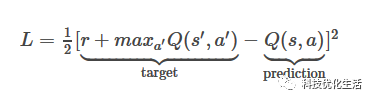
Q值更新:
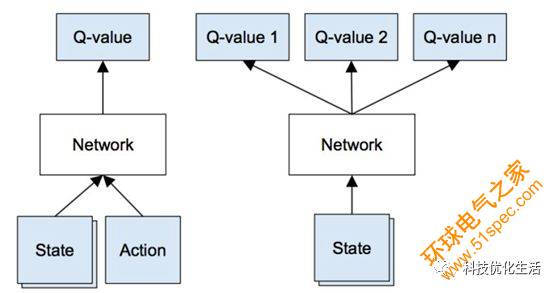
1)使用當前的狀態s通過神經網絡計算出所有動作的Q值
2)使用下一個狀態s’通過神經網絡計算出 Q(s’, a’),并獲取最大值max a’ Q(s’, a’)
3)將該動作a的目標Q值設為 r + γmax a’ Q(s’, a’),對于其他動作,把目標Q值設為第1步返回的Q值,使誤差為0
4)使用反向傳播來更新Q網絡權重。
帶有經驗回放的深度Q學習算法如下:

注:
1)經驗回放會使訓練任務更近似于通常的監督式學習,從而簡化了算法的調式和測試。
2)深度Q網絡之后,有好多關于 DQN 的改進。比如雙深度 Q 網絡(DoubleDQN),確定優先級的經歷回放和決斗網絡(Dueling Network)等。
策略搜索方法通過無梯度或梯度方法直接查找策略。無梯度的策略搜索算法可以選擇遺傳算法。遺傳方法依賴于評估一組智能體的表現。因此,對于具有許多參數的一大群智能體來說遺傳算法的使用成本很高。然而,作為黑盒優化方法,它們可以用于優化任意的不可微分的模型,并且天然能夠在參數空間中進行更多的探索。結合神經網絡權重的壓縮表示,遺傳算法甚至可以用于訓練大型網絡;這種技術也帶來了第一個直接從高維視覺輸入學習RL任務的深度神經網絡。
深度策略網絡

策略梯度

Actor-Critic算法將策略搜索方法的優點與學習到的價值函數結合起來,從而能夠從TD錯誤中學習,近來很受歡迎。

異步優勢Actor Critic 算法(A3C)結合 Policy 和 Value Function 的產物。

確定策略梯度(Deterministic Policy Gradient)算法

虛擬自我對抗 (FSP)

深度強化學習挑戰:
目前深度強化學習研究領域仍然存在著挑戰。
1)提高數據有效性方面;
2)算法探索性和開發性平衡方面;
3)處理層次化強化學習方面;
4)利用其它系統控制器的學習軌跡來引導學習過程;
5)評估深度強化學習效果;
6)多主體強化學習;
7)遷移學習;
8)深度強化學習基準測試。
。。。。。。
深度強化學習應用:
深度強化學習DRL應用范圍較廣,靈活性很大,擴展性很強。它在圖像處理、游戲、機器人、無人駕駛及系統控制等領域得到越來越廣泛的應用。
深度強化學習DRL算法已被應用于各種各樣的問題,例如機器人技術,創建能夠進行元學習(“學會學習”learning to learn)的智能體,這種智能體能泛化處理以前從未見過的復雜視覺環境。
結語:
強化學習和深度學習是兩種技術,但是深度學習可以用到強化學習上,叫做深度強化學習DRL。深度學習不僅能夠為強化學習帶來端到端優化的便利,而且使得強化學習不再受限于低維的空間中,極大地拓展了強化學習的使用范圍。深度強化學習DRL自提出以來, 已在理論和應用方面均取得了顯著的成果。尤其是谷歌DeepMind團隊基于深度強化學習DRL研發的AlphaGo,將深度強化學習DRL成推上新的熱點和高度,成為人工智能歷史上一個新的里程碑。因此,深度強化學習DRL很值得大家研究。深度強化學習將有助于革新AI領域,它是朝向構建對視覺世界擁有更高級理解的自主系統邁出的一步。難怪谷歌DeepMind中深度強化學習領頭人David Silver曾經說過,深度學習(DL) + 強化學習(RL) = 深度強化學習DRL=人工智能(AI)。深度強化學習應用范圍較廣,靈活性很大,擴展性很強。它在圖像處理、游戲、機器人、無人駕駛及系統控制等領域得到越來越廣泛的應用。
下一篇: PLC、DCS、FCS三大控
上一篇: 索爾維全系列Solef?PV